(Not-So-)Far From Normal
Outlier detection in all its glory

At first glance, the problems of detecting credit card fraud, COVID in wastewater, trashed highway stops, meth “smurfs” buying sudafed (yes, that’s the actual term), concussed athletes returning to the field, and speech patterns associated with brain and/or speech disorders appear to have nothing in common. But all of them are potential applications of outlier detection.
In any work modeling data, finding and dealing with outliers is a necessary part of the job. Here, we define outliers as points or individual observations that differ significantly from the rest of the dataset. They are sometimes referred to as anomalies. The inclusion of these aberrant measurement can potentially skew results from even simple statistical tests on the dataset. Further, when used in predictive modeling, the inclusion of outliers in the training set may render the model inaccurate or in the worst case, downright unusable.

In your intro stats class, you might have identified outliers with boxplots or heard that they will be easy to spot due to their placement no closer than three standard deviations (3σ) away from the mean. Although these can be indications that points are outliers, they will not be applicable if the main data is a series of clusters instead of one clean normal distribution.
There are three general approaches to dealing with outliers: labeling, accommodation, and identification. The first approach is to flag an outlier for further analysis; the second, to build a model that works with outliers included; and the third, to formally test its anomalous status. This post focuses solely on the third approach.
To better understand outlier detection, we will first generate a dataset with a constrained number of outliers. This article will thoroughly examine the math behind, usefulness of, and practical applications for outlier detection, and show how we may use it within this example. This article assumes a working knowledge of college calculus, and is targeted towards newcomers to data science.
First, we will lay the groundwork for understanding Benford’s Law and pattern recognition, why they are applicable, and how they can be used to find outliers. We then examine three other models for identifying outliers: distance-based, likelihood-based, and Gaussian mixture models.
Our Data
For the code implementation in this project, used the Credit Card Fraud Detection dataset from Kaggle. This dataset is a collection of 284,807 credit card transactions made by European cardholders in September 2013. Of these, 492 (0.1792%) are fraudulent. However, analysis is complicated by the presence of 28 variables that have been transformed to comply with legal privacy protection measures. The dataset features a total of 30 independent variables and then the classification column indicating whether the transaction is fraudulent or not.
Exploratory Data Analysis
Before we get to the juicy math bits, we need to make sure the data set is in order. In many cases, outlier detection falls under this aspect of data processing, but since we’re detecting rather than deleting, we’ll leave discussion of that approach for a separate post. Let’s start by bringing the data set into R and summarizing it:
Thankfully, the summary looks pretty good — the columns are in the formats we need, and we can go ahead and save the data without the class labels as a separate dataframe to manipulate later.
Now, let’s take an initial peek at the dataset through a couple plots. The plot to the left of the time of transaction vs. the amount of the transaction shows some obvious aberrant points.
However, the first Mystery Variable shows some serious divergence from expected patterns. Here we see clear outliers in both the transaction amount and the first transformed variable. Further inspection of all other variables shows outliers in every dimension. These remaining plots can be reproduced using the code associated with this post.
Thankfully, the summary looks pretty good — the columns are in the formats we need, and we can go ahead and save the data without the class labels as a separate dataframe to manipulate later.
Patterns & Benford’s Law

Nature follows distinctive patterns, but many of them are not necessarily intuitive. Pi, for example, is a naturally occurring number calculated by dividing the circumference of a perfect circle by its diameter.
The Golden Ratio, or phi (φ) is a naturally re-occurring ratio where (𝑎+𝑏)/𝑎=𝑎/𝑏. This ratio naturally occurs in the spiral arrangement of leaves such as the saucer plant as shown at left. The Fibonacci sequence also has a relationship to the golden ratio, as expressed by Binet’s formula (excluded for the purposes of length).
The interesting and unintuitive example that we’re building towards is Benford’s Law. When a dataset encompasses a huge range of values — we’re talking differences in building heights here, not human ages) — the leading digit of the values follows a pattern. This curious incidence was discovered in 1881 by Simon Newcomb, a scientist interested in why a physical lookup table for t-test values was more worn on certain pages than others.
Let’s suppose that we have a huge set of numbers gathered arbitrarily, like a complete set of number examples from math textbooks. If you were to look at every number not as a value, but a list of characters, you could make a list of the first character of all numbers. If you did this with every number in a corpus of math textbooks, in the list of first number characters (leading digit) you would see the number 1 more often (30%) than 2 (~17%) which shows up more often than 3 (~12.5%), etc. with decreasing differences in frequency. The mathematical representation is given by
Mahalanobis Distance
The Mahalanobis distance is a method for identifying outliers. It measures the squared distance from a point in multivariate space to the centroid of the points, and is calculated using the formula
where x-bar is a vector of the means for each variable (column of the dataset), and Sigma is the variance/covariance matrix, estimated from the data. In R, we will use the mahalanobis() function to look at credit card fraud.
To assess whether or not a distance qualifies as an outlier, the chi-squared distribution is used to determine the cutoff value. Anything above the cutoff value is then classified as an outlier, which in this case means fraudulent. This value can be calculated by choosing the desired quantile and setting the degrees of freedom equal to the number of predictor variables, shown here. A detailed proof of the relationship between the Mahalanobis distance and the chi-squared distribution can be found here.
This approach classified 20,981 points as outliers. This is considerably higher than the actual number of fraudulent cases! But are all the fraud cases accounted for in these outliers at least? Let’s check.
After correctly identifying 436 out of 492 fraudulent transactions, it seems like this could be a decently accurate method for spotting fraud! However, after taking into account the number of outliers that were incorrectly classified as fraud, the usefulness of this method takes a hit, as is reflected in the Precision-Recall curve.
To summarize, the Mahalanobis distance can detect outliers, but fraudulent transactions may not register as outliers when applying this method. Conversely, an unusual transaction does not necessarily mean that it is fraudulent. However, the Mahalanobis distance will only see that it does not follow the usual pattern, so using the distance-based method to detect fraud may lead to many false alarms.
Likelihood-based Approach
Since the Mahalanobis distance finds a squared distance, it’s good for amplifying outliers. However, it doesn’t necessarily give us context. What if we want to describe that size in the context of expectations?
Data points exist in some kind of distribution so that over time we should see a naturally occurring frequency of numbers. In sufficiently large numbers, under some conditions, the average of many datapoints (or some variant) fits a Gaussian or normal distribution.
In our case we have already described the distribution of Benford’s Law and seen what it looks like in practice. We can define this distribution as a specific type of multinomial distribution with nine categories (for the nine possible numbers). We can produce the probabilities in R using the dmultinom() function in the R library stats.
- x = vector of datapoints
- size = the total number of objects to put in K boxes, defaults to sum(x)
- prob = the number of classes in the multinomial distribution
- log =
TrueorFalse, calculate log probabilities
And now, for some math to explain log-likelihood and why we care about it.
Normal Likelihood:
The likelihood function itself is a way to compare an actual sample of data to a statistical model, and assess whether it fits or not. According to the statistical Law of Likelihood, the likelihood ratio measures how much evidence (aka observed data) supports one parameter value (aka hypothesis or expectation) versus another.
In Bayesian statistics, this is termed the Bayes Factor. One additional note: notice that all the pieces of the Mahalanobis Distance formula, this is a derivative of that.
Normal Log Likelihood
The log-likelihood doesn’t exactly tell us anything different than the likelihood themselves, they move in the same direction, but it has different properties that are convenient. For example, most common distributions that are used in estimation are approximately logarithmic. Furthermore, the overall log-likelihood of multiple events equals the sum of the log-likelihoods of the individual events. Due to the properties of logs, one last neat quality is that the likelihood ratio is equivalent to the numerator minus the denominator. Although it’s not hugely impactful, it’s pleasing.
Per our example, let’s take the enormous string of all the first digits of all the numbers and compare our data to the Benford’s Law equation. While we defined the equations above for the normal or Gaussian distribution, in this example we are comparing to a Benford distribution. The likelihood equation requires a distribution of some kind to hold meaning, and therefore must be adjusted any time a different distribution is used. In our case, the dmultinom() function will accept a given distribution and gracefully complete the remaining calculations.
Gaussian Mixture Models
Instead of assuming that all the data conforms to a singular curve, this approach begins with the assumption that the outliers fall in a different distribution from the observations. In other words, if we’re fitting a model, we think that the data in front of us is mostly from the model we want to build. However, this is mixed in with some data that doesn’t follow the same pattern.

This approach is typically characterized by assuming that the “regular” data is distributed as a single or a group of several normal curves. Here, we fit multiple normal curves to the data, find the characteristics of each distribution (mean, standard deviation, variance), and then calculate the probability that a point belongs to a given distribution. The distribution with the highest probability is selected as the class label.
As previously mentioned, a one-dimensional, or univariate, Gaussian is represented mathematically by
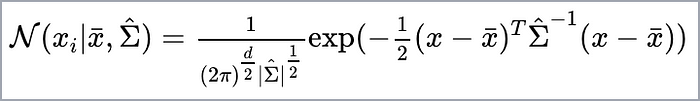
Likewise, the weighted Gaussian model is represented as a summation of the probability densities of individual Gaussian distributions, or
where, for cluster k in the set ϕ is the weight, x-bar is the mean, and Σ-hat is the covariance matrix (equivalent to the variance, or the square of the standard deviation, in the univariate model). We will continue to work with the dataset introduced above to give robust and comparable explorations of the capabilities of each of the different approaches to outlier detection.
To look at how this does with the credit card fraud dataset, we use the Mclust() function from the mclust package. Note that Mclust() will take quite a while to run on this dataset (even when you only look at the first 1,000 rows!), so make sure to budget time for it to do the thing.
Since this model is fitted using an expectation maximization approach, we know that it will attempt to fit the model to the data we have while also generalizing it enough that it will have predictive power — both traits that we desire in an outlier detection system.
For future study, it would likely be worthwhile to do some more specific feature engineering on the 30 unknown variables before running these models again. However, the credit card dataset is especially tricky due to the lack of transparency regard these features and how they have been reduced and/or transformed. More study is, as is almost always true, warranted here.
Conclusion
In the course of this tutorial, you’ve seen the mathematical underpinnings and practical implementations of three different outlier detection methods. However, many other implementations and practical applications exist, and are worth further exploration. If you’re interested in learning more, we have linked some further reading the following methods below:
Written in partnership with Kip McCharen and Emily Lien for SYS 6018 (not 6012, as the link says). The cited source code lives here.
SOURCES:
Michael, P. SYS 6018 Notes 11. https://mdporter.github.io/SYS6018/lectures/11-anomaly.pdf
https://schroderlawfirm.com/methamphetamine-what-is-smurfing/
https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h.htm
https://www.kaggle.com/mlg-ulb/creditcardfraud
https://en.wikipedia.org/wiki/Fibonacci_number#Binet's_formula
https://en.wikipedia.org/wiki/Simon_Newcomb
https://towardsdatascience.com/mahalonobis-distance-and-outlier-detection-in-r-cb9c37576d7d?gi=1f49b0c7f625
https://markusthill.github.io/mahalanbis-chi-squared/
https://stat.ethz.ch/R-manual/R-devel/library/stats/html/Multinom.html
https://heartbeat.fritz.ai/hands-on-with-feature-engineering-techniques-dealing-with-outliers-fcc9f57cb63b?gi=1d7ca2311928
https://www.r-bloggers.com/2020/01/area-under-the-precision-recall-curve/
https://towardsdatascience.com/mahalonobis-distance-and-outlier-detection-in-r-cb9c37576d7d
https://en.wikipedia.org/wiki/Likelihood_principle#law_of_likelihood
https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3293195/
https://www.rdocumentation.org/packages/xgboost/versions/0.4-4/topics/xgboost
https://www.semanticscholar.org/paper/Machine-learning-based-lithographic-hotspot-with-Ding-Wu/2dfc241726996cf997635cb19088087af6d8b5dd?fbclid=IwAR1PmEmPSrdGINIKG5mzwW8DakmeenLsv0uh_6mfcHyQHPlPssfT6CWRS1E
https://online.stat.psu.edu/stat504/node/60/?fbclid=IwAR2LIp2WMHF2VhfOSyPhtHcLiAOexL3k9mXXnnoUb_KcB2NYe07YaWSdqxw
